
Why AI Hallucinates and how you can control it.
‘In February 2024, a tribunal in Canada held Air Canada liable for a discount offered by its AI chatbot offered which did not existed as per company policy.’
‘Forbes reported that, a University study, found that at times LLM powered coding tools added or hallucinated references to packages that did not exist. About 20% of the code samples examined across 30 different Python and JavaScript LLM models returned references to non-existent packages. These AI code generations cybersecurity risks manifested in introduction of vulnerabilities in software supply chain which could be used by hackers.’
These are not just chatbot or AI malfunction — but warning signs of a deep trouble called AI Hallucination! What happens when AI provides false information with complete confidence which people trust?
So, What is an AI Hallucination?
AI hallucination refers to a phenomenon where AI systems particularly Generative AI tools generate outputs that are misleading, incorrect or fabricated. Often humans trust these output as truth which is then used to take decisions. At times this can be harmless while at times it can have serious repercussions.
Consider a AI powered medical system recommending an incorrect prescription, or a business chatbot misleading customers. These scenarios highlight why AI hallucinations are not just a technical flaw but a real-world problem which AI professionals, Cybersecurity experts, AI ethics thought leaders and domain experts must address.
How AI Hallucination Hurting Us?
AI-generated misinformation can have implications across most of the aspects of our lives, society and the economy:
- Misinformation Spread: AI Hallucinations can generate false news or misleading statements, may spread confusion among readers, viewers or listeners. With increasing usage of Generative AI in content generation this is a problem.
For example, in October 2024, a lawsuit by Dow Jones and New York Post against a popular AI organization argued that hallucinating fake news and attributing it to a real paper was illegal and potentially confused readers.
- Legal and Ethical Risks: AI Hallucinations can results in inaccurate legal or medical output information or advice which can lead to real harm.
In the case of Gauthier v. Goodyear Tire & Rubber Co., a Texas attorney, Brandon Monk, faced significant legal repercussions for relying on generative AI to draft a legal brief that included citations to non-existent cases and fabricated quotations.
- Business Reputational Damage: Companies using AI-powered chatbots risk misinforming customers, eroding trust, and facing potential lawsuits. For example, the
Air Canada case mentioned in the introduction highlights how the discounts offered by the chatbots can cause business and reputational damage.
- Security Risk: AI Hallucination in cybersecurity may generate false alarm for non-existent threats. In the introduction we have mentioned how AI hallucination can generated codes with non-existent references thus causing software vulnerabilities. Therefore developers should be aware of the risks of AI Code Generation and their fixes.
- Bias and discrimination: AI hallucinations can lead to reinforced stereotypes, and flawed decision making affecting a particular class or group.
For example, it was reported in 2019 that a widely used healthcare prediction algorithm was biased against black Americans revealing significant racial bias.
Why Does AI Make Up Things?
AI does not know everything in advance, rather it learns from data and then predicts. So AI hallucinations have to do with issue during training data and methodology or lack of fact checking during generation. There are several reasons why it may produce misleading information.
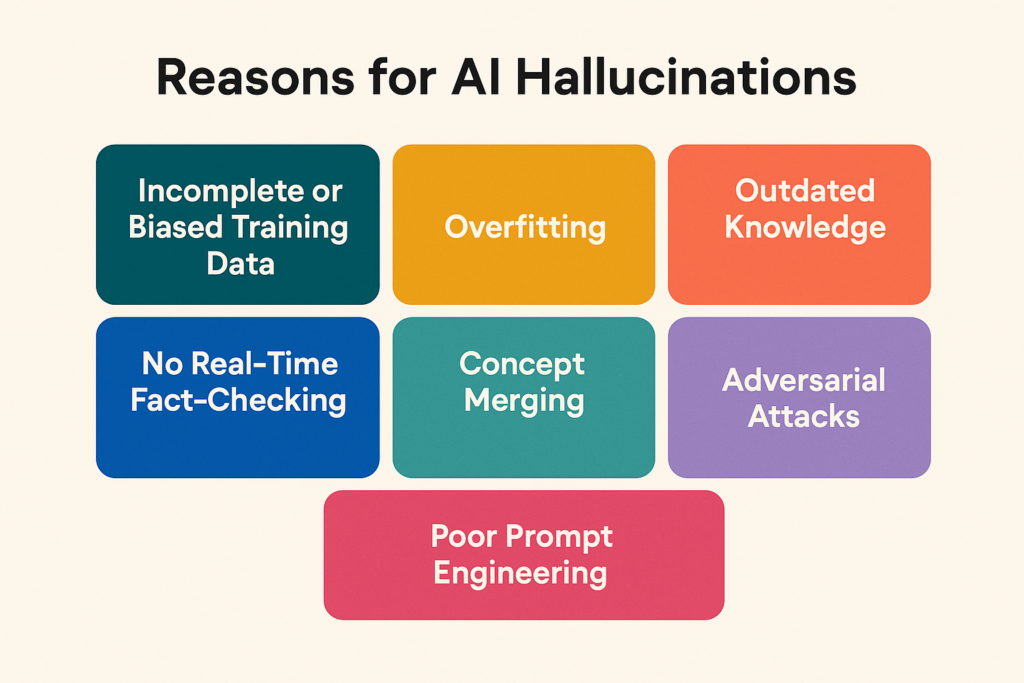
Figure: AI Hallucination Causes
1. Incomplete or Biased Training Data
Artificial Intelligence systems learn patterns, knowledge, and relationships from the data they are trained on. If the training dataset is not comprehensive—meaning it is incomplete, inaccurate, or biased—then the resulting AI model is likely to inherit those limitations. This can lead to AI Hallucination manifesting as the generation of misleading, incorrect, or completely fabricated responses that appear plausible on the surface but are fundamentally flawed.
Incomplete data may omit crucial scenarios or populations, while biased data may reflect systemic inequalities, stereotypes, or underrepresentation of specific groups. As a result, the AI model may generalize poorly or reinforce existing misconceptions.
Example: A medical AI trained only on Western healthcare data might misdiagnose a disease prevalent in India due to a lack of relevant training.
2. Overfitting
Overfitting happens when an AI model learns too much from its training data—so much that it memorizes specific details rather than understanding general patterns. Overfitting is a common challenge in machine learning where a model becomes excessively tailored to the specific data it was trained on. Rather than learning the underlying patterns or general rules that can be applied to new, unseen data, an overfitted model ends up memorising the training dataset—including its noise, outliers, and even errors. This leads to poor performance and AI hallucination when the model is exposed to real-world scenarios or slightly different inputs.
Overfitted models often show very high accuracy on training data but fail miserably on testing or production data. This is because they confuse spurious patterns for meaningful signals and rely on associations that don’t hold outside the narrow context of the training set.
This problem can become severe in large language models or generative AI systems, where the training data spans vast and diverse sources. The model might latch onto irrelevant correlations or repeat memorized content, believing it to be meaningful or factual resulting in AI hallucinations.
Example: A stock prediction AI trained on 10 years of data may learns to recognize patterns, but instead of spotting real trends, it may memorizes random fluctuations. When applied to real trading, it fails because the patterns it relied on were just coincidences, not reliable predictors.
3. Outdated Knowledge
Most AI models are trained on static datasets that reflect the state of the world at the time of training. After that, they do not automatically learn about new events, discoveries, or changes unless manually updated or connected to a real-time data source. This results in a knowledge cut-off, beyond which the model cannot accurately answer time-sensitive questions leading to AI hallucination.
This limitation becomes critical in fast-evolving domains like law, healthcare, finance, or politics. Users may mistakenly assume the AI is current, leading to reliance on outdated or inaccurate information.
Example: An AI trained in 2021 may still claim Joe Biden is the current U.S. president in 2025.
4. No Real-Time Fact-Checking
Most AI models generate responses based on static training data and don’t verify facts against live or authoritative sources. This means they may confidently provide outdated or incorrect information, especially in fast-changing fields like law, medicine, or finance resulting in AI hallucination.
Without access to current databases or websites, AI responses can sound credible while being factually wrong. Even when integrated with search tools, some models still synthesize answers without directly quoting reliable sources.
Example: A legal AI assistant may provide outdated tax laws if it does not pull the latest information from government websites.
5. Concept Merging
AI models often form associations based on patterns in training data. When unrelated terms appear together frequently, the AI may mistakenly infer a connection, leading to responses that blend unrelated ideas into a fictional narrative.
This is known as concept merging, and while it may seem amusing in casual use, it can cause AI hallucinations and spread misinformation if users interpret the output as factual.
Example: If asked, “What is the connection between Shakespeare and skateboarding?” AI may generate an entirely fictional link based on unrelated correlations.
6. Poor Prompt Engineeing
The quality of the prompt directly influences the quality of the AI’s response. Poorly framed, vague, or ambiguous prompts can lead the model to guess, generalize, or even fabricate information in an attempt to fulfill the request. Since most generative AI models are designed to be helpful and coherent, they may prioritize producing something plausible-sounding—even if it isn’t accurate.
When users fail to provide clear context, constraints, or specificity, the AI model may default to speculative or “filler” content, increasing the risk of AI hallucination. This is particularly risky in professional settings where factual correctness is critical.
Example: Suppose the GDPR compliance team asks following query to AI, “Tell me the penalty provision in the act?”. In such scenario AI may respond by mentioning penalty provision in any given act.
7. Adversarial attacks
AI systems can be intentionally misled by bad actors using techniques like prompt injection, data poisoning, or model manipulation. These attacks exploit vulnerabilities in how AI learns or responds, causing it to produce biased, harmful, or false outputs.
Such attacks are especially dangerous in domains like news, healthcare, or finance, where misinformation can have real-world impact. The AI may unknowingly adopt and repeat falsehoods planted during training or runtime resulting in AI hallucinations.
Example: Imagine an AI model trained to generate news articles. A malicious actor manipulates its training data by injecting thousands of fake articles containing false political narratives. Over time, the AI “learns” these fabricated stories as real events.
So, How to Keep AI’s Hallucination in Check
While AI hallucinations cannot be eliminated entirely, several approaches can help mitigate the risk.
1. Improve Training Data
One of the most effective ways to reduce AI hallucinations is to train models on high-quality, diverse, and representative datasets. When AI is exposed to data that accurately reflects different geographies, cultures, languages, and domains, it develops a more balanced understanding and is less likely to generate biased or fabricated responses.
Diverse training data ensures that the AI can generalize better across various scenarios and user queries. It also helps reduce the risk of skewed outputs caused by underrepresented groups or topics, which are common in narrowly focused datasets.
Example: A medical system implemented globally and trained on diverse data from different ethnicity, gender, race, geography may hallucinate less than the one trained only on a particular race, ethnicity, gender or geography.
2. Use Retrieval-Augmented Generation (RAG)
RAG systems enhance the reliability of AI by combining real-time information retrieval with generative capabilities. Instead of depending solely on what the AI model learned during its initial training, RAG allows the system to dynamically fetch relevant documents—from internal databases, websites, or repositories—and use them as context for generating responses.
This significantly reduces AI hallucinations because the AI grounds its answers in verifiable, up-to-date sources rather than trying to guess or fill gaps from memory. RAG is particularly useful in business environments, where policies, regulations, or product details may change frequently.
To get the best results from a RAG system, retrieval improvement techniques must be carefully optimized—through better indexing, semantic search, and relevance ranking—to ensure the AI pulls the most accurate and relevant content.
Example: A RAG-powered chatbot can search the company policy documents about returns and refunds. It can use this information to generate proper response for customer queries about refunds.
3. Human Oversight (HITL – Human in the Loop)
In high-stakes domains like healthcare, legal systems, recruitment, and finance, AI should never function in isolation. Human-in-the-loop (HITL) is a crucial practice where human experts supervise, review, or override AI decisions to ensure outcomes are fair, ethical, and accurate.
Even the most advanced AI models can make errors, reflect bias, or hallucinate information. Human oversight adds a layer of accountability and critical judgment that machines lack—especially when dealing with ambiguous, sensitive, or exceptional cases.
Incorporating HITL is not just a technical safeguard against AI hallucinations, but also a legal and ethical necessity in many regulated industries.
Example: A recruitment AI screening resumes should have final human review to ensure fair hiring practices.
4. Fine Tuning Models
Fine-tuning is the process of adapting a pre-trained AI model by training it further on a specific, curated dataset relevant to a particular task, domain, or organization. While general-purpose models are trained on diverse internet-scale data, fine-tuning helps specialize them for narrow use cases such as legal analysis, healthcare support, cybersecurity operations, or internal enterprise knowledge.
This additional training improves the model’s domain-specific understanding, enhances response quality, and significantly reduces hallucinations by reinforcing accurate patterns and terminology relevant to that field.
Fine-tuned models are especially useful when the general model is not familiar with nuanced or confidential information that isn’t available in public datasets.
Example: An AI model fine-tuned on legal data can provide better responses related to Legal aspects as compared to a general pre-trained Large Language Model.
5. Ground Responses in Verifiable Data
To increase trust and reduce AI hallucinations, AI systems should be designed to anchor their responses in verifiable and credible data sources. Instead of producing speculative, vague, or overly generalized answers, the AI should cite specific documents, links, or references that users can cross-check.
This approach not only improves accuracy but also boosts user confidence by offering transparency. Grounding is especially important in sectors like education, healthcare, legal, or enterprise settings, where decision-making depends on factual correctness.
Modern AI systems increasingly include citation features or integrate with retrieval systems to show the origin of the information being presented. This can be a safeguard against the dangers of AI hallucination as the user can cross check the response.
Example: Now a days some chatbots based by popular LLMs don’t just generate text responses but also provide sources and references backing their responses.
6. Enable User Feedback and Continuous Learning
An essential step toward building reliable AI systems is enabling user feedback mechanisms. By allowing users to rate, flag, or comment on AI-generated responses, developers and organizations can identify inaccuracies, biases, or misleading outputs that may not surface during testing.
Feedback loops serve two key purposes: they help improve model performance over time, and they act as a safeguard by catching AI hallucinations that slip through. When paired with human review and periodic updates, feedback-driven refinement supports a continuous learning cycle, even if the underlying model isn’t retrained in real-time.
This approach ensures the AI system evolves with real-world usage and remains aligned with user expectations and domain standards.
Example: A customer service chatbot allowing users to report incorrect responses for review and refinement.
7. Structured and Context Rich Prompts
To reduce AI hallucinations caused by vague or ambiguous prompts, it’s important to apply prompt engineering techniques that guide the AI toward accurate, grounded responses. This includes being explicit about the task, providing context, and, when necessary, offering examples. Some well-known strategies include zero-shot prompting (asking without examples), few-shot prompting (giving a few examples), chain-of-thought prompting (encouraging step-by-step reasoning), and instruction prompting (clearly stating the format and goal). These methods help steer the model away from speculation and toward reliable outputs—especially in professional domains like compliance, law, or medicine.
Example: Instead of asking, “What is the penalty in the act?”, a more effective prompt would be: “What are the key penalty provisions in GDPR for violation of duties of data controllers?”
8. Securing AI
AI hallucinations can also be triggered or worsened by security vulnerabilities such as unauthorized data manipulation, adversarial attacks, or data poisoning. Strengthening the security of AI systems is essential not just for protecting sensitive data, but also for maintaining the integrity and reliability of the model’s outputs.
Attackers can intentionally inject misleading data, manipulate training inputs, or exploit prompt weaknesses to induce hallucinations or force harmful behavior from the AI. Securing the full AI lifecycle; from data collection and model training to deployment and monitoring; helps mitigate these risks.
To get started, organizations can follow frameworks like the OWASP Top 10 Risks and Mitigation for LLMs and GenAI applications, which outlines common risks (e.g., prompt injection, insecure plugins, overreliance on output) and practical mitigation techniques.
Example: If a chatbot connected to a company’s knowledge base lacks access controls or input validation, an attacker might insert misleading documents. The AI may then use this corrupted content to generate inaccurate responses, leading to reputational or legal damage. Robust AI security practices help prevent such vulnerabilities.
While the risk of AI hallucinations can never be entirely eliminated, the strategies outlined above—such as improving training data, grounding responses in facts, and enforcing robust security—can significantly reduce their frequency and impact, leading to safer and more trustworthy AI systems.
By combining technical solutions like Retrieval-Augmented Generation with human oversight and continuous feedback loops, organizations can strike the right balance between automation and accountability.
Final Thoughts: Keeping AI’s Imagination in Check
AI is a powerful and transformative technology, capable of automating tasks, generating insights, and accelerating innovation across industries. However, despite its potential, it has a critical flaw—when faced with incomplete or unfamiliar input, it can “hallucinate” or make up information that sounds plausible but is completely false. This tendency to fabricate content is not just a technical quirk; it can carry significant consequences. While some AI hallucinations may seem harmless or amusing, others can lead to serious legal liabilities, ethical dilemmas, or financial losses, especially when decisions are made based on inaccurate outputs.
To address this, organizations must adopt a multi-layered approach: improving training data quality, incorporating real-time fact-checking mechanisms, fine-tuning models on domain-specific content, and maintaining strong human oversight in high-risk scenarios. These strategies not only minimize hallucinations but also help in developing AI systems that are more transparent, responsible, and trustworthy.
As AI continues to evolve and become embedded in everyday processes—from customer service to healthcare and legal advisory—both businesses and individuals must remain vigilant. Because when AI confidently delivers false information, and that information is acted upon, the stakes can be alarmingly high.